Build a web crawler with Queues and Browser Rendering
This tutorial explains how to build and deploy a web crawler with Queues, Browser Rendering, and Puppeteer.
Puppeteer is a high-level library used to automate interactions with Chrome/Chromium browsers. On each submitted page, the crawler will find the number of links to Cloudflare.com and take a screenshot of the site, saving results to KV.
You can use Puppeteer to request all images on a page, save the colors used on a site, and more.
Prerequisites
To continue, you will need:
- A recent version of Node.js and npm installed.
- A subscription to Workers Paid, required for using Queues.
- Access to the Browser Rendering API, currently in open beta.
1. Build the crawler Worker
You will first need to create KV namespaces and queue required for the crawler before creating a new Worker, setting up bindings, and writing the crawler script.
Set up KV namespaces
To set up KV namespaces:
- Log in to the Cloudflare dashboard.
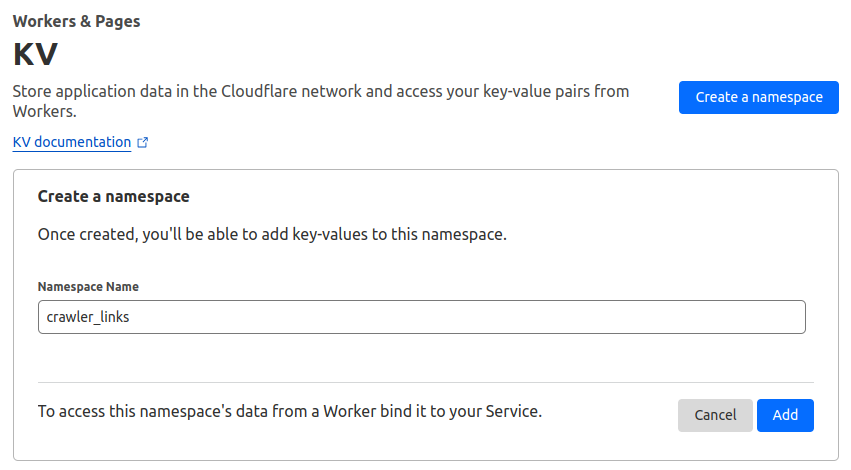
- Go to Workers & Pages > KV.
- Select Create a namespace, enter
crawler_links, and select Add. Repeat to create another KV namespace calledcrawler_screenshots.
Set up a Queue
To set up a Queue:
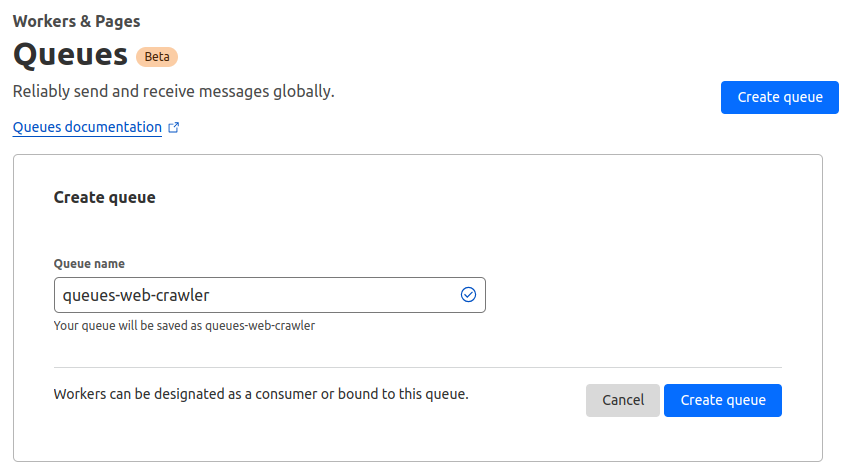
- Log in to the Cloudflare dashboard.
- Go to Workers & Pages > Queues.
- Select Create queue.
- Enter a queue name and select Create queue.
2. Create a Worker
Create a new Worker with the C3 (create-cloudflare-cli) CLI, a command-line tool designed to help you setup and deploy Workers to Cloudflare as fast as possible.
Create a Worker$ npm create cloudflare@latest # or yarn create cloudflare
C3 will then prompt you for some information on your Worker.
- Provide a name for your Worker. This is also the name of the new directory where the Worker will be created.
- For the question
What type of application do you want to create?, select"Hello World" Worker. - For the question
Would you like to use TypeScript? (y/n), selecty. - For the question
Do you want to deploy your application?, selectn.
This will create the crawler Worker.
3. Configure your Worker
In the wrangler.toml file, add a Browser Rendering binding. Adding a Browser Rendering binding gives the Worker access to a headless Chromium instance you will control with Puppeteer. Add the bindings for KV namespaces and queue you created previously, which will allow you to access KV and the queue from the Worker.
wrangler.tomlname = "queues-web-crawler"
main = "src/index.ts"
compatibility_date = "2023-06-09"
node_compat = true
browser = { binding = "CRAWLER_BROWSER", type = "browser" }
kv_namespaces = [ { binding = "CRAWLER_SCREENSHOTS_KV", id = "<crawler_screenshots namespace ID here>" }, { binding = "CRAWLER_LINKS_KV", id = "<crawler_links namespace ID here>" }
]
[[queues.consumers]] queue = "<queue name here>" max_batch_timeout = 60
[[queues.producers]] queue = "<queue name here>" binding = "CRAWLER_QUEUE"
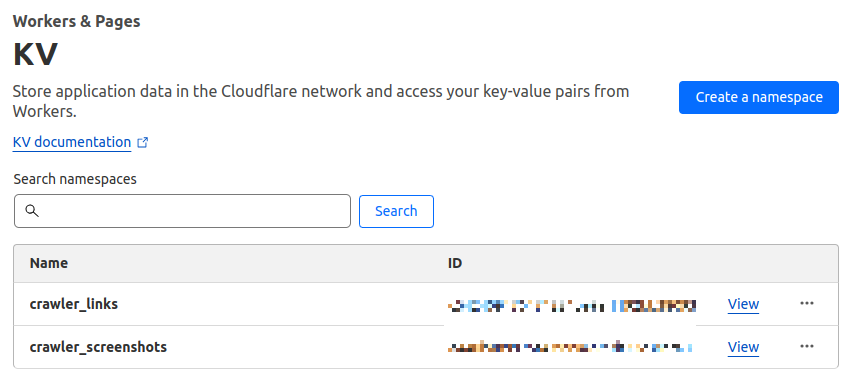
To find the KV namespace IDs in the Cloudflare dashboard, select Workers & Pages > KV. The namespace IDs are shown to the right of each KV namespace.
Add a max_batch_timeout of 60 seconds to the consumer because Browser Rendering has a limit of two new browsers per minute per account. This timeout waits up to a minute before collecting queue messages into a batch. The Worker will then remain under this browser invocation limit.
Change the usage_model to unbound. This allows your crawler to take advantage of higher CPU time limits.
Refer to Worker limits to learn more about usage models.
4. Add bindings to environment
Add the bindings to the environment interface in src/index.ts, so TypeScript correctly types the bindings. Type the queue as Queue<any>. The following step will show you how to change this type.
src/index.tsimport { BrowserWorker } from "@cloudflare/puppeteer";
export interface Env { CRAWLER_QUEUE: Queue<any>; CRAWLER_SCREENSHOTS_KV: KVNamespace; CRAWLER_LINKS_KV: KVNamespace; CRAWLER_BROWSER: BrowserWorker;
}
5. Submit links to crawl
Add a fetch() handler to the Worker to submit links to crawl.
src/index.tstype Message = { url: string;
};
export interface Env { CRAWLER_QUEUE: Queue<Message>; // ... etc.
}
export default { async fetch(req, env): Promise<Response> { await env.CRAWLER_QUEUE.send({ url: await req.text() }); return new Response("Success!"); },
} satisfies ExportedHandler<Env>;
This will accept requests to any subpath and forwards the request’s body to be crawled. It expects that the request body only contains a URL. In production, you should check that the request was a POST request and contains a well-formed URL in its body. This has been omitted for simplicity.
6. Crawl with Puppeteer
Add a queue() handler to the Worker to process the links you send.
src/index.tsimport puppeteer from "@cloudflare/puppeteer";
import robotsParser from "robots-parser";
async queue(batch: MessageBatch<Message>, env: Env): Promise<void> { let browser: puppeteer.Browser | null = null; try { browser = await puppeteer.launch(env.CRAWLER_BROWSER); } catch { batch.retryAll(); return; }
for (const message of batch.messages) { const { url } = message.body;
let isAllowed = true; try { const robotsTextPath = new URL(url).origin + "/robots.txt"; const response = await fetch(robotsTextPath);
const robots = robotsParser(robotsTextPath, await response.text()); isAllowed = robots.isAllowed(url) ?? true; // respect robots.txt! } catch {}
if (!isAllowed) { message.ack(); continue; }
// TODO: crawl! message.ack(); }
await browser.close();
},
This is a skeleton for the crawler. It launches the Puppeteer browser and iterates through the Queue’s received messages. It fetches the site’s robots.txt and uses robots-parser to check that this site allows crawling. If crawling is not allowed, the message is ack‘ed, removing it from the Queue. If crawling is allowed, you can continue to crawl the site.
The puppeteer.launch() is wrapped in a try...catch to allow the whole batch to be retried if the browser launch fails. The browser launch may fail due to going over the limit for number of browsers per account.
src/index.tstype Result = { numCloudflareLinks: number; screenshot: ArrayBuffer;
};
const crawlPage = async (url: string): Promise<Result> => { const page = await (browser as puppeteer.Browser).newPage();
await page.goto(url, { waitUntil: "load", });
const numCloudflareLinks = await page.$$eval("a", (links) => { links = links.filter((link) => { try { return new URL(link.href).hostname.includes("cloudflare.com"); } catch { return false; } }); return links.length; });
await page.setViewport({ width: 1920, height: 1080, deviceScaleFactor: 1, });
return { numCloudflareLinks, screenshot: ((await page.screenshot({ fullPage: true })) as Buffer) .buffer, };
};
This helper function opens a new page in Puppeteer and navigates to the provided URL. numCloudflareLinks uses Puppeteer’s $$eval (equivalent to document.querySelectorAll) to find the number of links to a cloudflare.com page. Checking if the link’s href is to a cloudflare.com page is wrapped in a try...catch to handle cases where hrefs may not be URLs.
Then, the function sets the browser viewport size and takes a screenshot of the full page. The screenshot is returned as a Buffer so it can be converted to an ArrayBuffer and written to KV.
To enable recursively crawling links, add a snippet after checking the number of Cloudflare links to send messages recursively from the queue consumer to the queue itself. Recursing too deep, as is possible with crawling, will cause a Durable Object Subrequest depth limit exceeded. error. If one occurs, it is caught, but the links are not retried.
src/index.ts// const numCloudflareLinks = await page.$$eval("a", (links) => { ...
await page.$$eval("a", async (links) => { const urls: MessageSendRequest<Message>[] = links.map((link) => { return { body: { url: link.href, }, }; }); try { await env.CRAWLER_QUEUE.sendBatch(urls); } catch {} // do nothing, likely hit subrequest limit
});
// await page.setViewport({ ...
Then, in the queue handler, call crawlPage on the URL.
src/index.ts// in the `queue` handler:
// ...
if (!isAllowed) { message.ack(); continue;
}
try { const { numCloudflareLinks, screenshot } = await crawlPage(url); const timestamp = new Date().getTime(); const resultKey = `${encodeURIComponent(url)}-${timestamp}`; await env.CRAWLER_LINKS_KV.put( resultKey, numCloudflareLinks.toString(), { metadata: { date: timestamp } } ); await env.CRAWLER_SCREENSHOTS_KV.put(resultKey, screenshot, { metadata: { date: timestamp }, }); message.ack();
} catch { message.retry();
}
// ...
This snippet saves the results from crawlPage into the appropriate KV namespaces. If an unexpected error occurred, the URL will be retried and resent to the queue again.
Saving the timestamp of the crawl in KV helps you avoid crawling too frequently.
Add a snippet before checking robots.txt to check KV for a crawl within the last hour. This lists all KV keys beginning with the same URL (crawls of the same page), and check if any crawls have been done within the last hour. If any crawls have been done within the last hour, the message is ack‘ed and not retried.
src/index.tstype KeyMetadata = { date: number;
};
// in the `queue` handler:
// ...
for (const message of batch.messages) { const sameUrlCrawls = await env.CRAWLER_LINKS_KV.list({ prefix: `${encodeURIComponent(url)}`, });
let shouldSkip = false; for (const key of sameUrlCrawls.keys) { if (timestamp - (key.metadata as KeyMetadata)?.date < 60 * 60 * 1000) { // if crawled in last hour, skip message.ack(); shouldSkip = true; break; } } if (shouldSkip) { continue; }
let isAllowed = true; // ...
7. Deploy your Worker
To deploy your Worker, run the following command:
$ npx wrangler deploy
You have successfully created a Worker which can submit URLs to a queue for crawling and save results to KV.
Refer to the GitHub repository for the complete tutorial, including a front end deployed with Pages to submit URLs and view crawler results.